Publications/Reports

Recent studies have started integrating large language models (LLMs) into AutoML frameworks to enhance model search efficiency and configuration prediction, yet challenges remain in adapting these methods for energy-efficient searches across vast configuration spaces, as they often neglect energy consumption metrics. As a result, we introduce the Language-Enhanced Shrinkage Search (LESS), a plug-and-play method that utilizes the analytical capabilities of LLMs to enhance the energy efficiency of existing hyperparameter optimization techniques.
Shuguang Dou, Jiale Zhao, Xinyang Jiang, Junyao Gao, Yuge Zhang, Bo Li, Dongsheng Li
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) in 2025, CCF A

We propose a novel paradigm that leverages the benefits of image perturbations for rectifying data distributions. Our method, called DPL (Deep Perturbation Learning), introduces new insights into utilizing image perturbations and focuses on improving generalizability on normal samples, rather than resisting adversarial attacks.
Ding Qi, Jian Li, Junyao Gao, Shuguang Dou, Ying Tai, Jianlong Hu, Bo Zhao, Yabiao Wang, Chengjie Wang, Cairong Zhao
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) in 2025, CCF A

We introduce Video-based Person Search (VPS), a task that tracks individuals and their trajectories in raw video scenes, enhancing performance in practical applications. Due to the lack of suitable datasets and privacy concerns, we created the first VPS dataset using virtual environments, featuring diverse continuous video scenes. Paired with an evaluation framework, this dataset assesses both retrieval performance and trajectory quality.
Ding Qi, Shuguang Dou, Jian Liu, Huaixuan Cao, Hao Zhang, Dongsheng Jiang, Cairong Zhao
Proceedings of the Computer Vision and Pattern Recognition Conference Workshop in 2025
pdf / Dataset / Website Online

We propose a universal dataset distillation framework, named UniDD, a task-driven diffusion model for diverse DD task
Ding Qi, Jian Li, Junyao Gao, Shuguang Dou, Ying Tai, Jianlong Hu, Bo Zhao, Yabiao Wang, Chengjie Wang, Cairong Zhao
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR Oral) in 2025
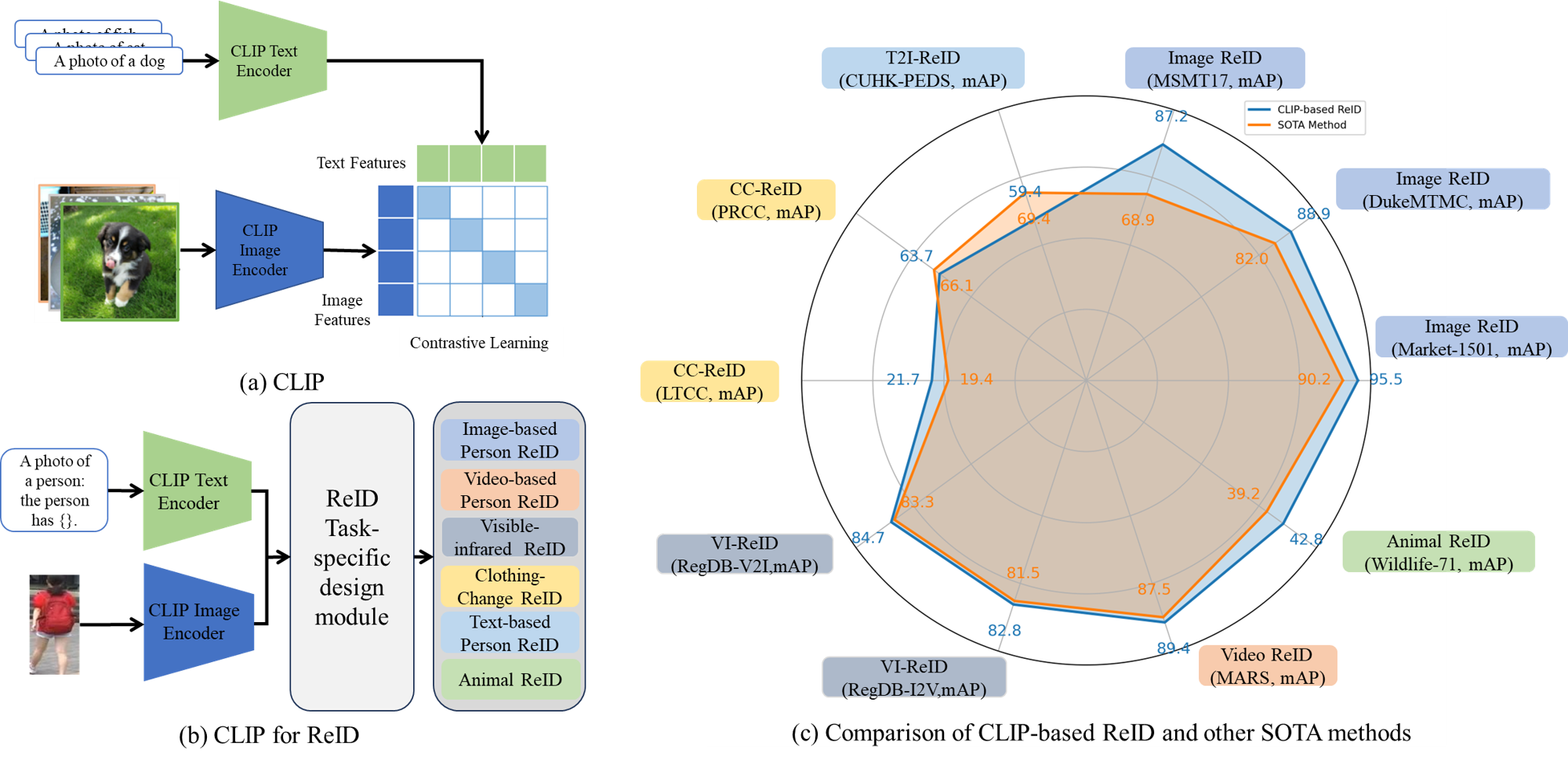
In this paper, we present a comprehensive survey of large pre-training models for ReID, which we refer to as the “One for All” approach. This paradigm leverages large-scale pre-training models, such as self-supervised or language-image pre-training models, as general feature extractors adaptable to multiple ReID tasks.
Yubing Sun, Shuguang Dou, Ding Qi, Yanping Li, Jiale Zhao and Cairong Zhao
Web Conference Workshop on Multimedia Object Re-ID:Advancements, Challenges, and Opportunities (MORE 2025)

Current research on DC mainly focuses on image classification, with less exploration of object detection. As a remedy, we propose DCOD, the first dataset condensation framework for object detection. It initially storing key localization and classification information into model parameters, and then reconstructing synthetic images via model inversion.
Ding Qi, Jian Li, Jinlong Peng, Shuguang Dou, Jialin Li, Bo Zhao, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Cairong Zhao
Neural Information Processing Systems (NeuPIS) in 2024, CCF A

Most existing MI attack methods focus on classification models, while Re-ID follows a distinct paradigm for training and inference. Re-ID is a fine-grained recognition task that involves complex feature embedding, and the model outputs commonly used by existing MI algorithms, such as logits and losses, are inaccessible during inference. We propose a novel MI attack method based on the distribution of inter-sample similarity, which involves sampling a set of anchor images to represent the similarity distribution that is conditioned on a target image.
Junyao Gao, Xinyang Jiang, Shuguang Dou, Dongsheng Li, Duoqian Miao, Cairong Zhao
International Journal of Computer Vision (IJCV) in 2024, CCF A
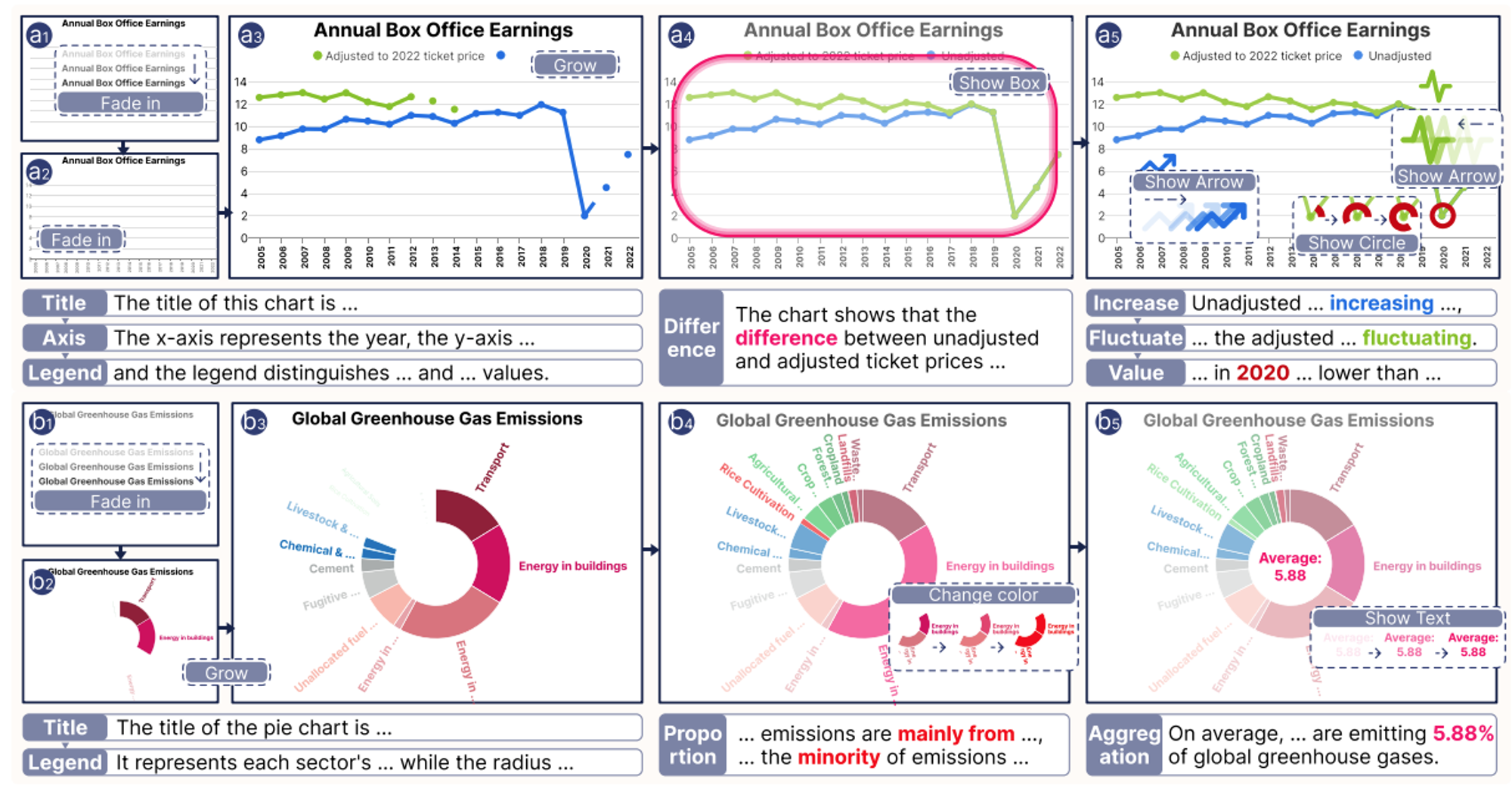
Data charts are prevalent across various fields due to their efficacy in conveying complex data relationships. However, static charts may sometimes struggle to engage readers and efficiently present intricate information, potentially resulting in limited understanding. We introduce “Live Charts,” a new format of presentation that decomposes complex information within a chart and explains the information pieces sequentially through rich animations and accompanying audio narration.
Lu Ying, Yun Wang, Haotian Li, Shuguang Dou, Haidong Zhang, Xinyang Jiang, Huamin Qu, Yingcai Wu
IEEE Transactions on Visualization and Computer Graphics (T-VCG) in 2024, CCF A
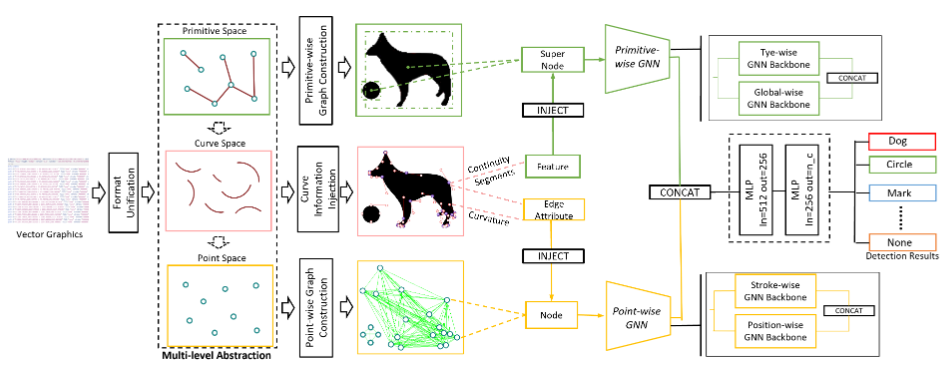
The conventional approach to image recognition has been based on raster graphics, which can suffer from aliasing and information loss when scaled up or down. In this paper, we propose a novel approach that leverages the benefits of vector graphics for object localization and classification. Our method, called YOLaT (You Only Look at Text), takes the textual document of vector graphics as input, rather than rendering it into pixels. We propose YOLaT++ to learn Multi-level Abstraction Feature Learning from Primitive Shapes to Curves and Points. On the other hand, given few public datasets focus on vector graphics, data-driven learning cannot exert its full power on this format. We provide a large-scale and challenging dataset for Chart-based Vector Graphics Detection and Chart Understanding, termed VG-DCU, with vector graphics, raster graphics, annotations, and raw data drawn for creating these vector charts.
Shuguang Dou, Xinyang Jiang, Lu Liu, Lu Ying, Caihua Shan, Yifei Shen, Xuanyi Dong, Yun Wang, Dongsheng Li, Cairong Zhao
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) in 2024, CCF A
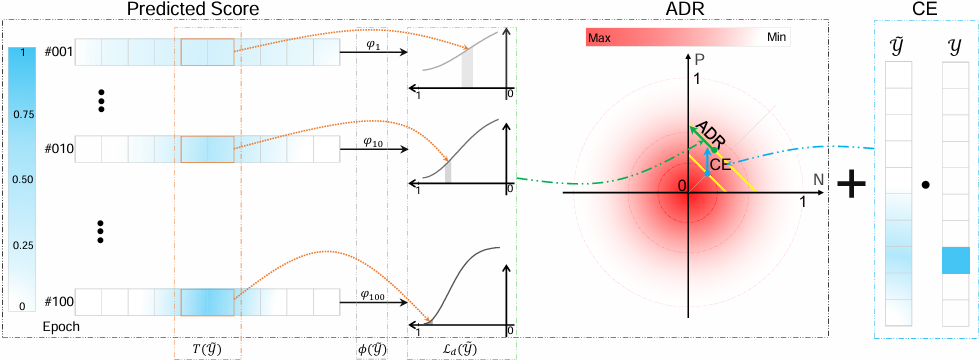
How to improve discriminative feature learning is central in classification. In this paper, we embrace the real-world data distribution setting in that some classes share semantic overlaps due to their similar appearances or concepts. Regarding this hypothesis, we propose a novel regularization to improve discriminative learning. We first calibrate the estimated highest likelihood of one sample based on its semantically neighboring classes, then encourage the overall likelihood predictions to be deterministic by imposing an adaptive exponential penalty.
Qingsong Zhao, Yi Wang, Shuguang Dou, Chen Gong, Yin Wang and Cairong Zhao
International Journal of Computer Vision (IJCV) in 2024, CCF A
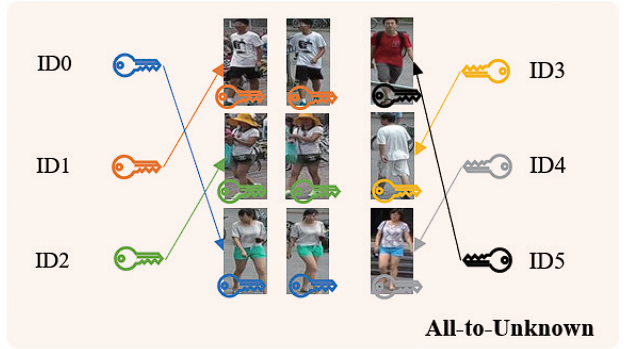
Existing backdoor attack methods follow an all-to-one or all-to-all attack scenario, where all the target classes in the test set have already been seen in the training set. However, ReID is a much more complex fine-grained open-set recognition problem, where the identities in the test set are not contained in the training set. To ameliorate this issue, we propose a novel backdoor attack on deep ReID under a new all-to-unknown scenario, called Dynamic Triggers Invisible Backdoor Attack (DT-IBA). Instead of learning fixed triggers for the target classes from the training set, DT-IBA can dynamically generate new triggers for any unknown identities.
Wenli Sun, Xinyang Jiang, Shuguang Dou, Dongsheng Li, Duoqian Miao, Cheng Deng, Cairong Zhao
IEEE Transactions on Information Forensics and Security (T-IFS) in 2023, CCF A
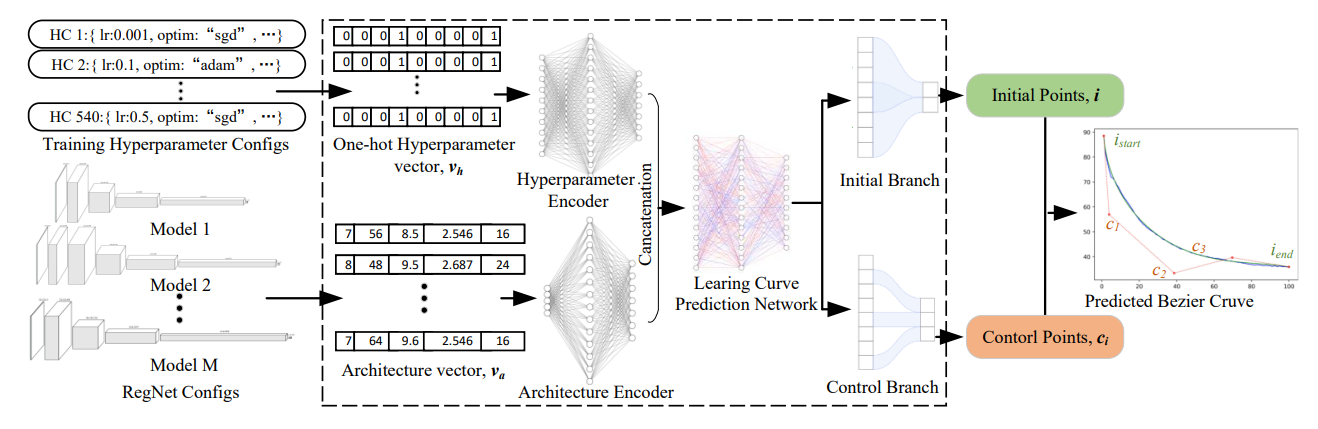
We present the first large-scale energy-aware benchmark that allows studying AutoML methods to achieve better trade-offs between performance and search energy consumption, named EA-HAS-Bench. EA-HAS-Bench provides a large-scale architecture/hyperparameter joint search space, covering diversified configurations related to energy consumption.
Shuguang Dou, Xinyang Jiang, Cairong Zhao, Dongsheng Li
International Conference on Learning Representations (ICLR) in 2023, Spotlight
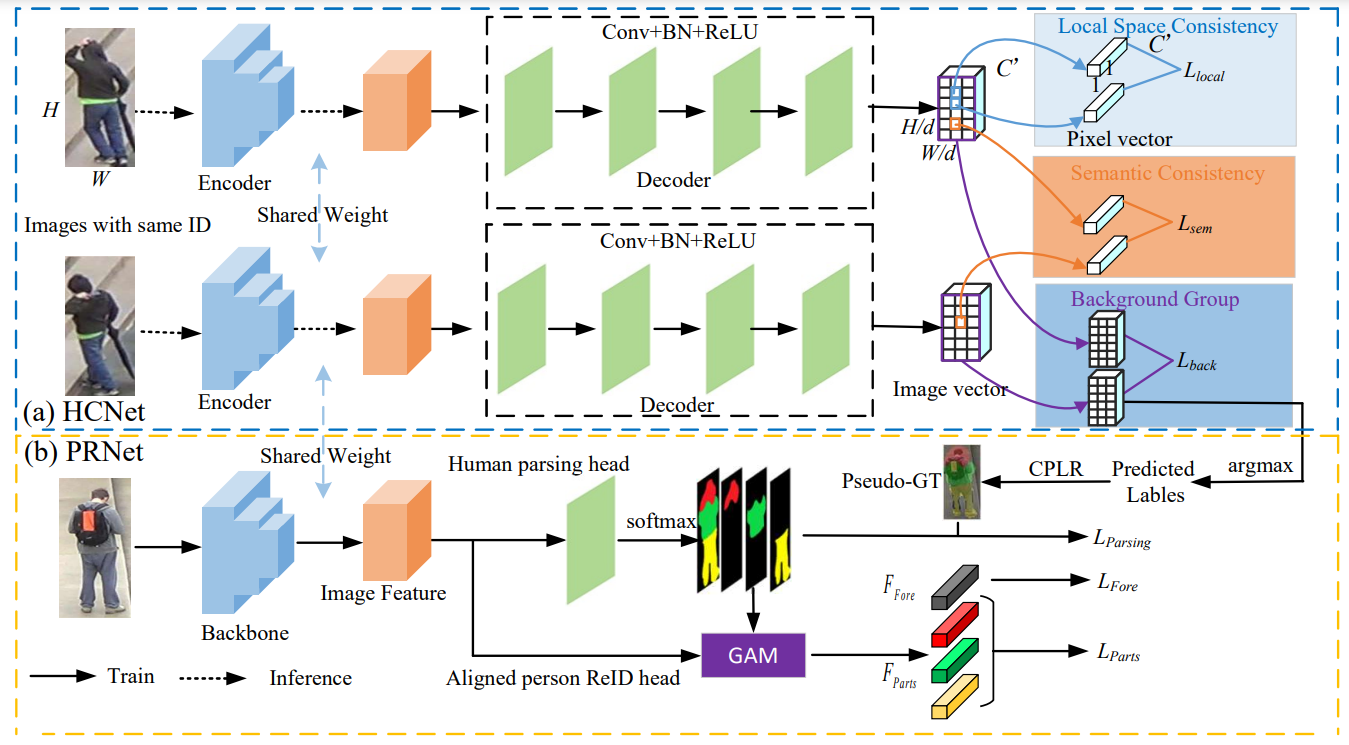
We propose a novel Human Co-parsing Guided Alignment (HCGA) framework that alternately trains the human co-parsing network and the ReID network, where the human co-paring network is trained in a weakly supervised manner to obtain paring results without any extra annotation.
Shuguang Dou, Cairong Zhao, Xinyang Jiang, Shanshan Zhang, Member, IEEE, Wei-Shi Zheng, Wangmeng Zuo, Senior Member, IEEE
IEEE Transactions on Image Processing (T-IP) in 2022, CCF A

One of the key challenges to the X-ray security checkis to detect the overlapped items in backpacks or suitcases in the X-ray images. Most existing methods improve the robustness of models to the object overlapping problem by enhancing the underlying visual information such as colors and edges. However, this strategy ignores the situations in that the objects have similar visual clues as to the background, and objects overlapping each other. Since the two cases rarely appear in existing datasets, we contribute a novel dataset – Cutters and Liquid Containers X-ray Dataset (CLCXray) to complete the related research.
Cairong Zhao*, Liang Zhu*, Shuguang Dou, Weihong Deng, and Liang Wang, Fellow, IEEE (*Co-First Authors)
IEEE Transactions on Information Forensics and Security (T-IFS) in 2022, CCF A
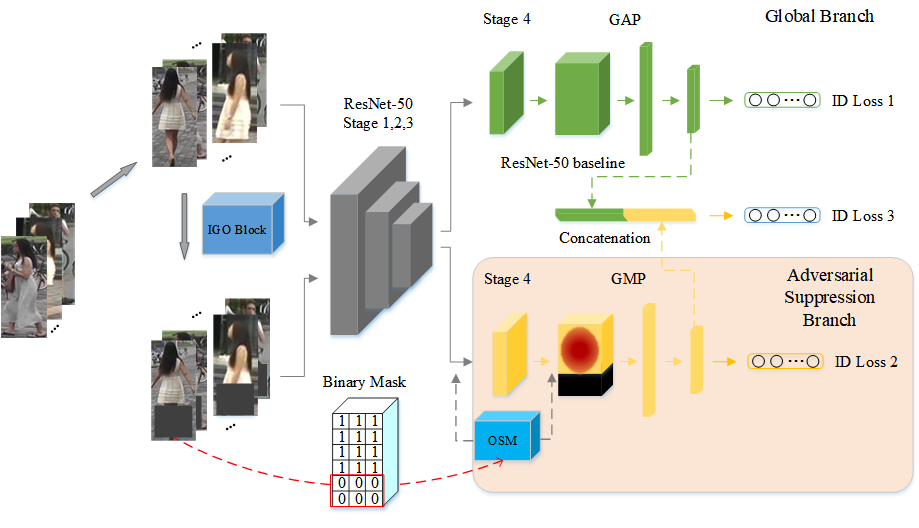
To address the occlusion problem, we propose a novel Incremental Generative Occlusion Adversarial Suppression (IGOAS) network.
Cairong Zhao*, Xinbi Lv*, Shuguang Dou*, Shanshan Zhang, Member, IEEE, Jun Wu, Senior Member, IEEE, and Liang Wang, Fellow, IEEE (*Co-First Authors)
Accepted by IEEE Transactions on Image Processing (T-IP) in 2022, CCF A
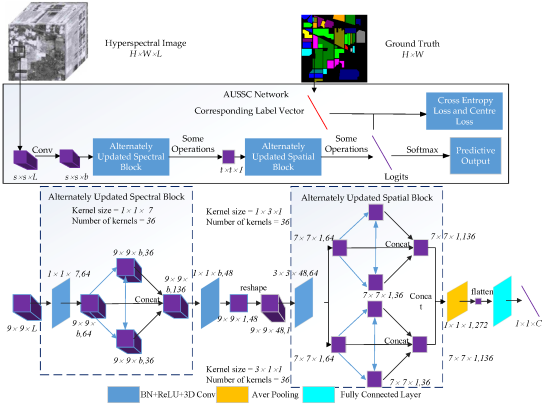
The connection structure in the convolutional layers of most deep learning-based algorithms used for the classification of hyperspectral images (HSIs) has typically been in the forward direction. In this study, an end-to-end alternately updated spectral–spatial convolutional network (AUSSC) with a recurrent feedback structure is used to learn refined spectral and spatial features for HSI classification.
Wenju Wang, Shuguang Dou^, Sen Wang (^Corresponding Author and First Student Author)
Remote sensing 2019
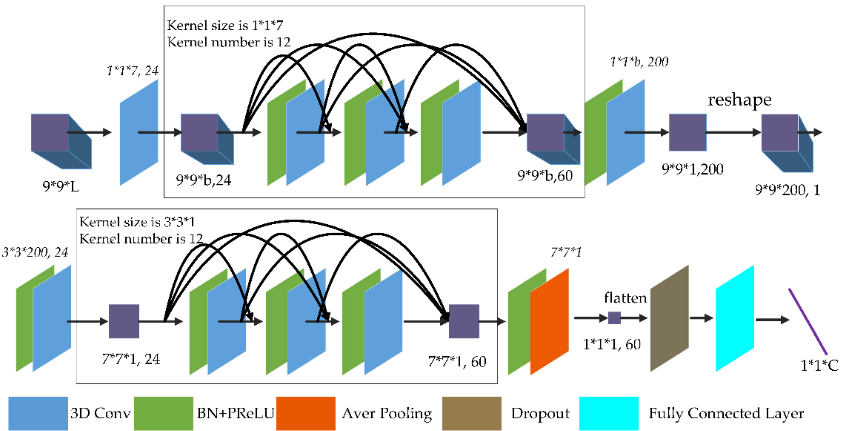
To reduce the training time and improve accuracy, in this paper we propose an end-to-end fast dense spectral–spatial convolution (FDSSC) framework for HSI classification.
Wenju Wang, Shuguang Dou^, Zhongmin Jiang and Liujie Sun (^Corresponding Author and First Student Author)
Remote sensing 2018(ESI Highly Cited Paper Citation 300+)
Theses

Learning deep features from 3D point cloud for classification and retrieval. This work will be done before 12/2019.
Shuguang Dou
Master Thesis, College of Communication and Art Design, University of Shanghai for Science and Technology; December, 2019