Invisible Backdoor Attack with Dynamic Triggers against Person Re-IDentification
Wenli Sun*
Xinyang Jiang
Shuguang Dou
Dongsheng Li
Duoqian Miao
Cheng Deng
Cairong Zhao*
Abstract
—In recent years, person Re-IDentification (ReID) has rapidly progressed with wide real-world applications but is also susceptible to various forms of attack, including proven vulnerability to adversarial attacks. In this paper, we focus on the backdoor attack on deep ReID models. Existing backdoor attack methods follow an all-to-one or all-to-all attack scenario, where all the target classes in the test set have already been seen in the training set. However, ReID is a much more complex fine-grained open-set recognition problem, where the identities in the test set are not contained in the training set. Thus, previous backdoor attack methods for classification are not applicable to ReID. To ameliorate this issue, we propose a novel backdoor attack on deep ReID under a new all-to-unknown scenario, called Dynamic Triggers Invisible Backdoor Attack (DT-IBA). Instead of learning fixed triggers for the target classes from the training set, DT-IBA can dynamically generate new triggers for any unknown identities. Specifically, an identity hashing network is proposed to first extract target identity information from a reference image, which is then injected into the benign images by image steganography. We extensively validate the effectiveness and stealthiness of the proposed attack on benchmark datasets and evaluate the effectiveness of several defense methods against our attack. <p style="text-align:justify; text-justify:inter-ideograph;"> We raise a new and rarely studied backdoor attack risk on the ReID task, which is quantified by our proposed new all-to-unknown attack scenario. The new all-to-unknown attack scenario and a novel corresponding method are proposed to realize adversary mismatch and target person impersonation by dynamic triggers, which are able to dynamically alter the poisoned image’s identity to any target identity outside the training set.
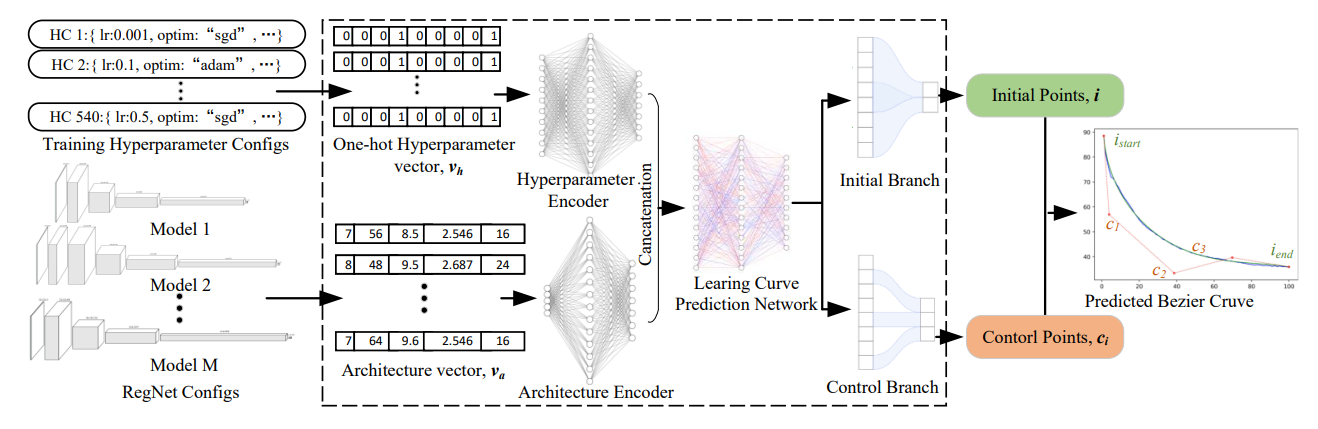 </div>
<figcaption>
</div>
<figcaption>
Figure 1.Overview of Bezier Curve-based Surrogate Model. HC denotes Hyperparameter configuration. </figcaption>
NAS-Bench-101 do not directly provide training energy cost but use model training time as the training resource budget, which as verified by our experiments, is an inaccurate estimation of energy cost. HW-NAS-bench provides the inference latency and inference energy consumption of different model architectures but also does not provide the search energy cost.
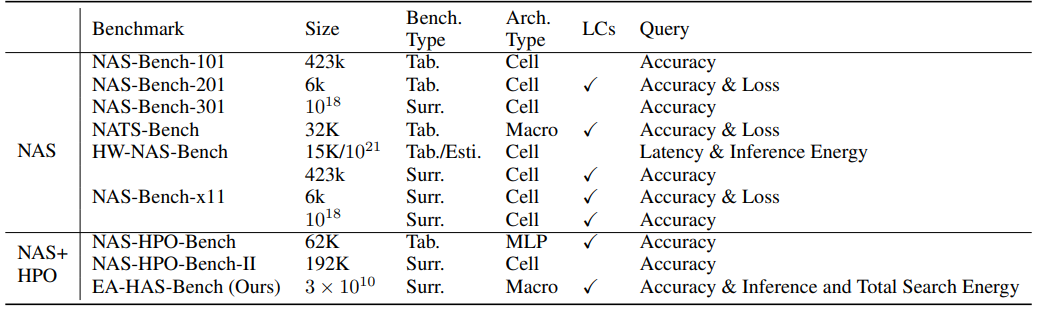
Dataset Overview
EA-HAS-Bench’s Search Space
Unlike the search space of existing mainstream NAS-Bench that focuses only on network architectures, our EA-HAS-Bench consists of a combination of two parts: the network architecture space- RegNet and the hyperparameter space for optimization and training, in order to cover diversified configurations that affect both performance and energy consumption. The details of the search space are shown in Table.
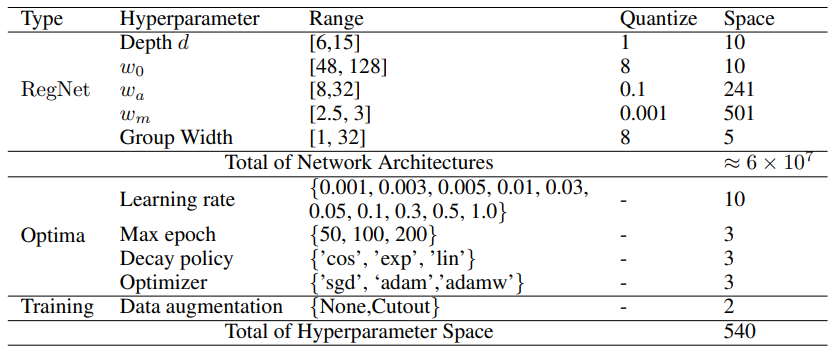
Evaluation Metrics
The EA-HAS-Bench dataset provides the following three types of metrics to evaluate different configurations:
- Model Complexity: parameter size, FLOPs, number of network activations (the size of the output tensors of each convolutional layer), as well as the inference energy cost of the trained model.
- Model Performance: full training information including training, validation, and test accuracy learning curves.
- Search Cost: energy cost (in kWh) and time (in seconds).
Dataset Statistics
The left plot shows the validation accuracy box plots for each NAS benchmark in CIFAR-10. The right plot shows a comparison of training time, training energy consumption (TEC), and test accuracy in the dataset.
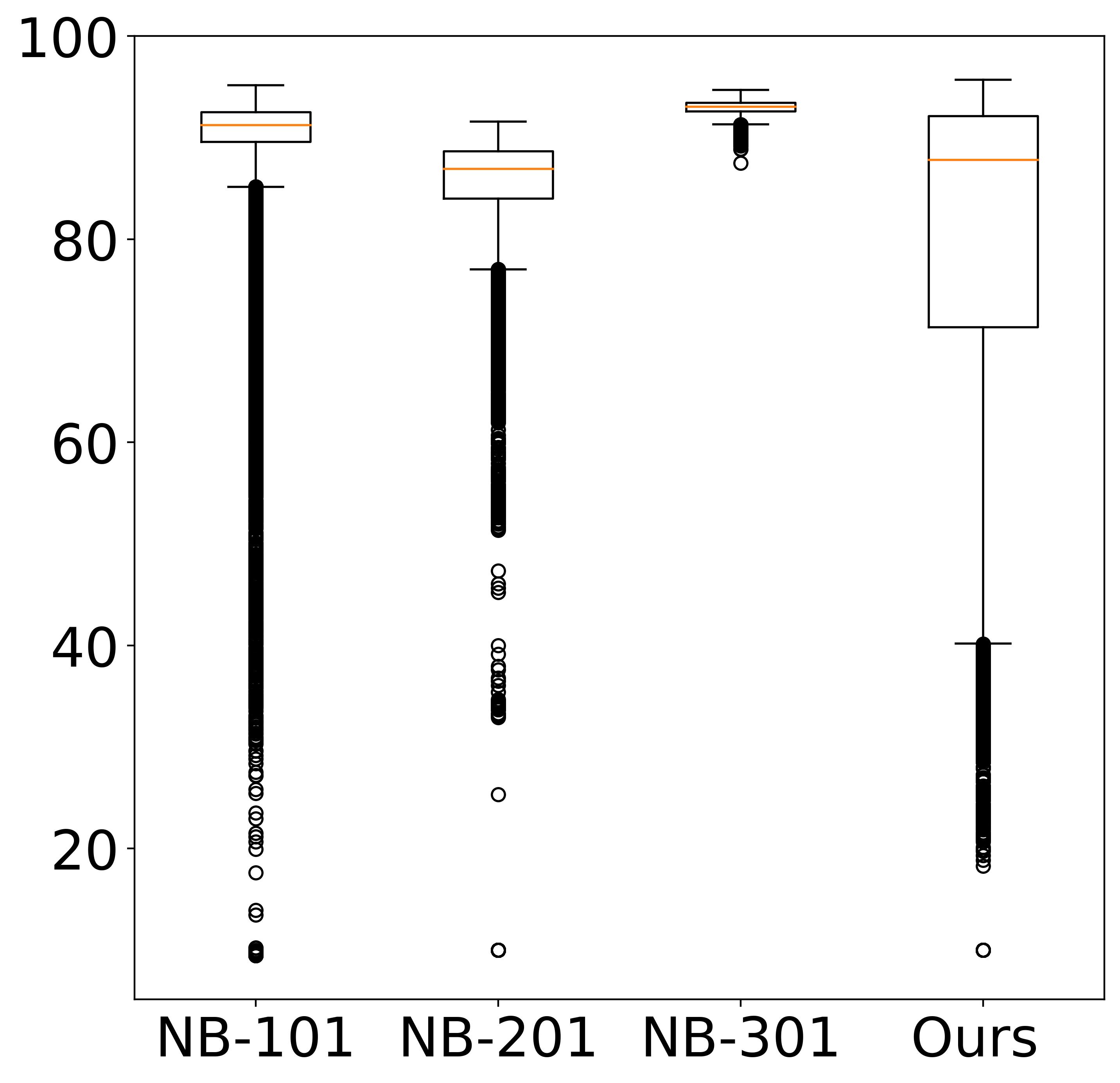
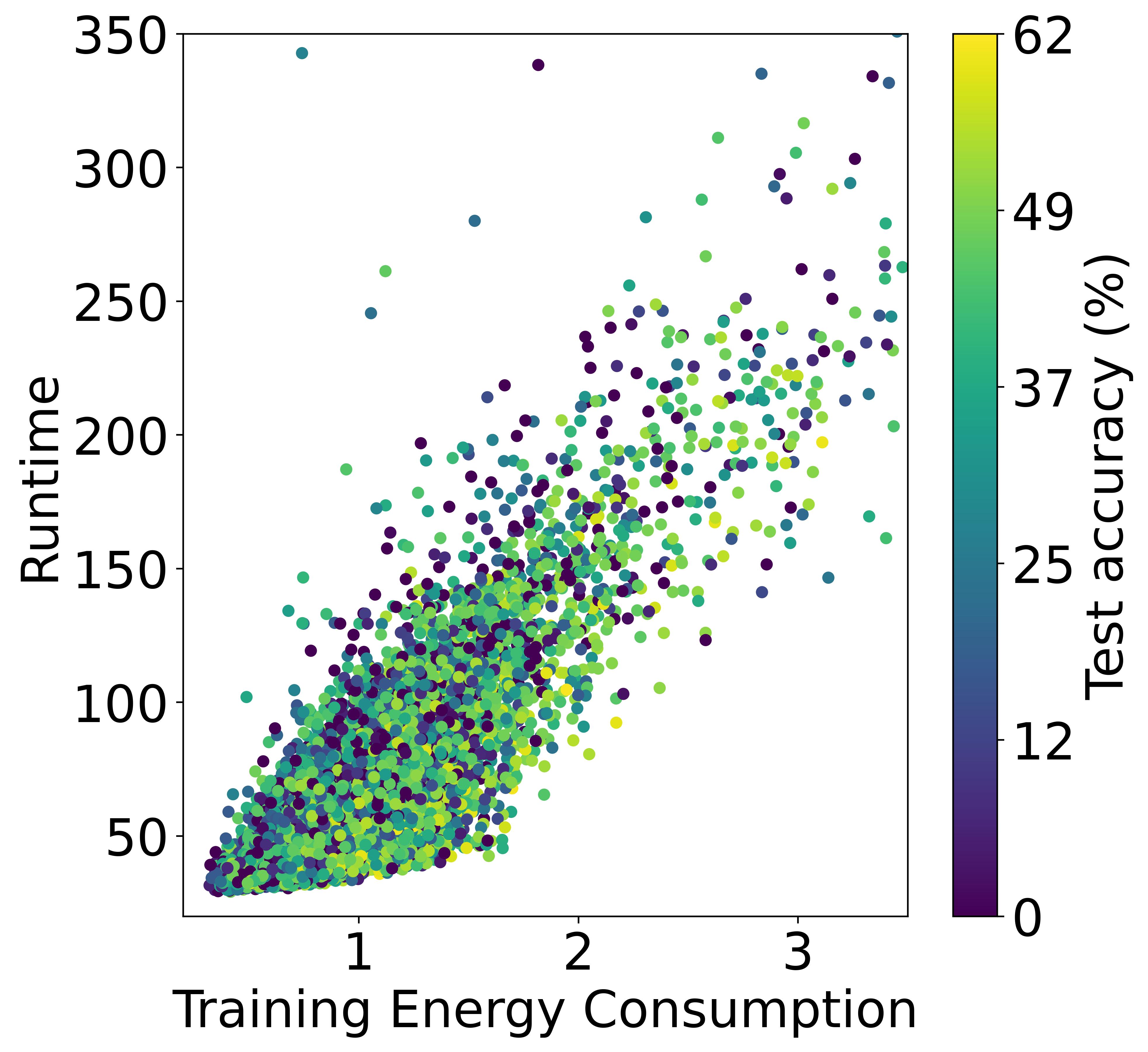
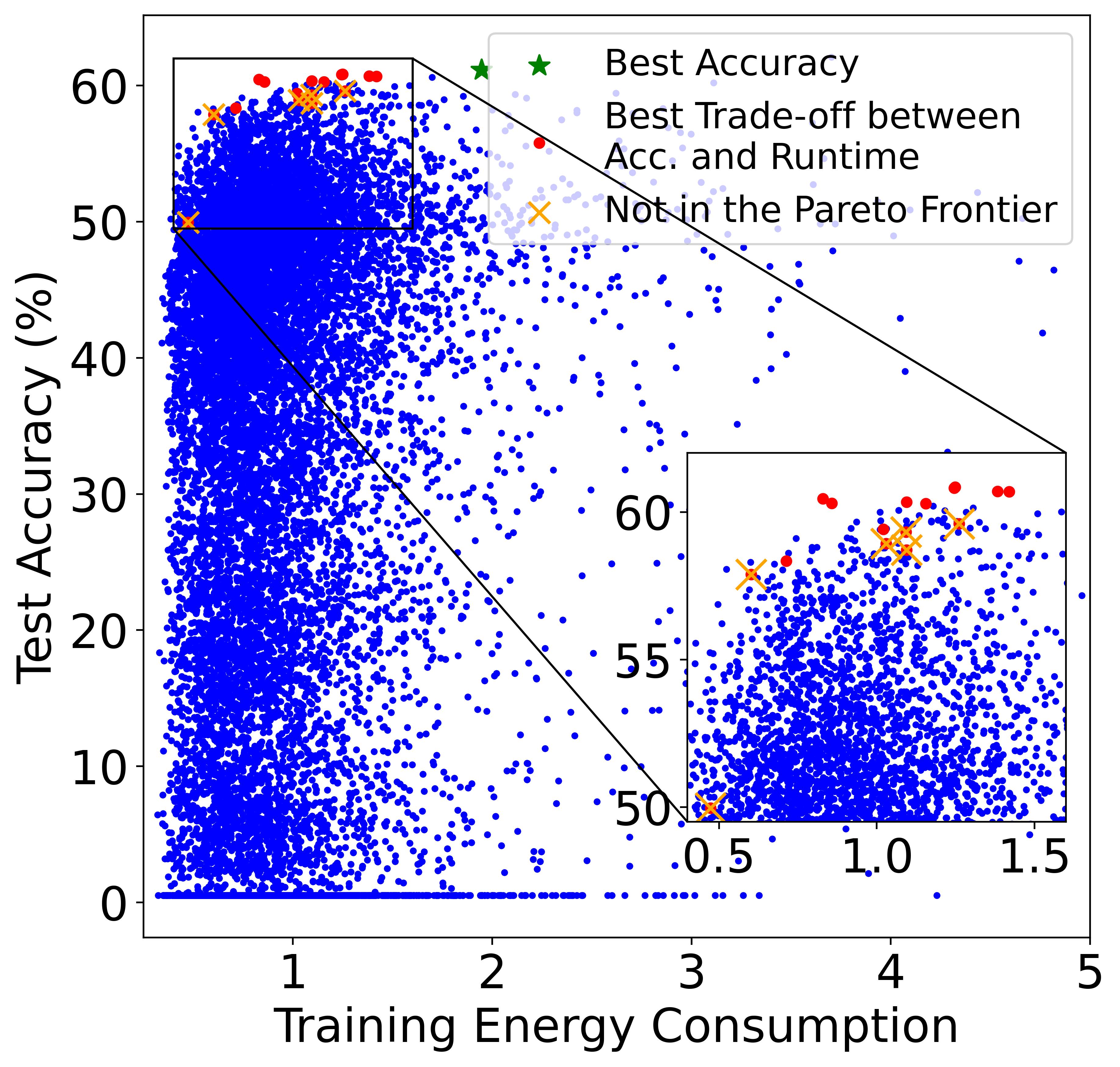
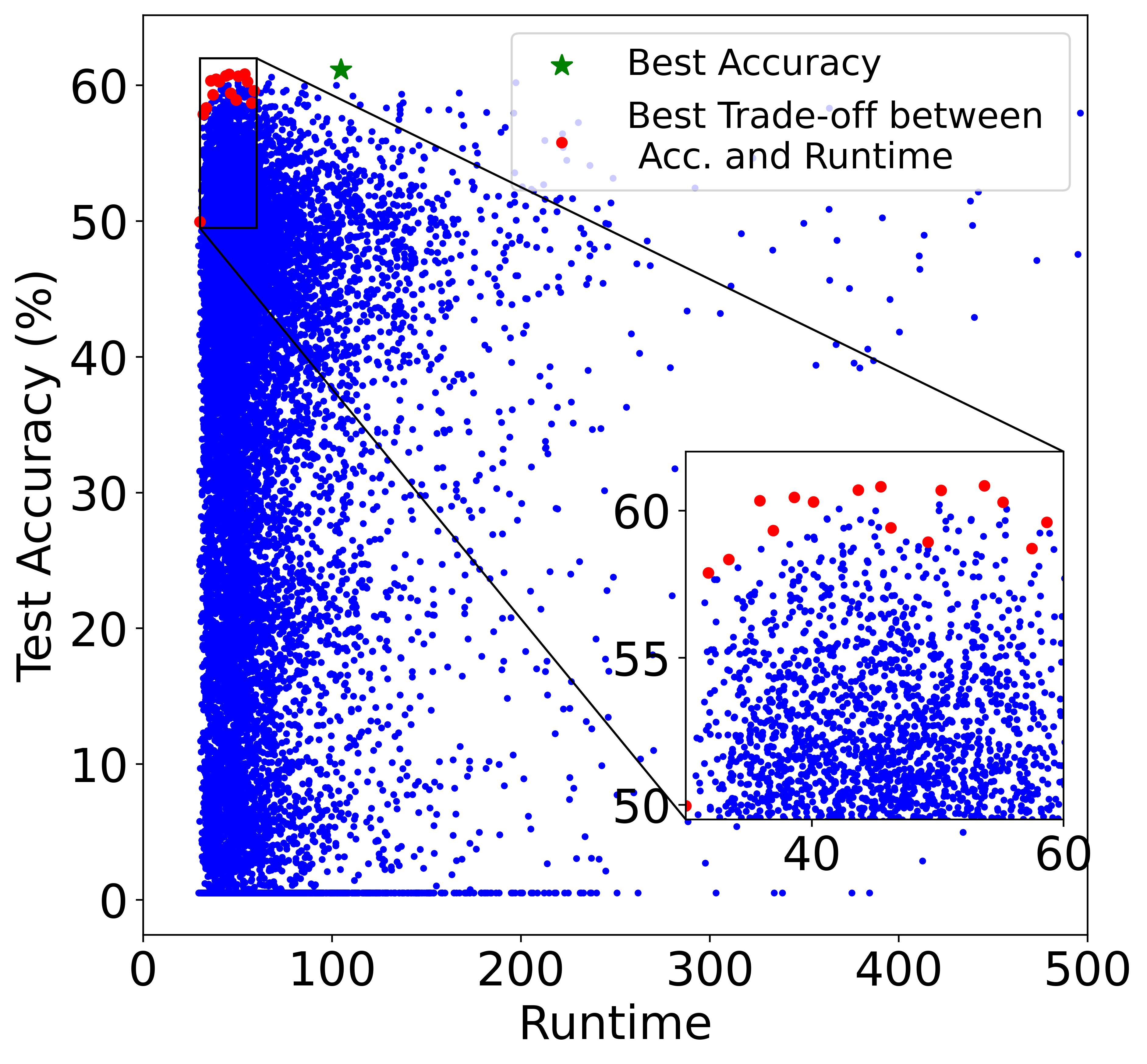
Although training the model for a longer period is likely to yield a higher energy cost, the final cost still depends on many other factors including power (i.e., consumed energy per hour). The left and right plots of Figure also verifies the conclusion, where the models in the Pareto Frontier on the accuracy-runtime coordinate (right figure) are not always in the Pareto Frontier on the accuracy-TEC coordinate (left figure), showing that training time and energy cost are not equivalent.
Paper
- Paper: PDF
Please consider citing if this work and/or the corresponding code and dataset are useful for you:
@inproceedings{ea23iclr,
title={EA-HAS-Bench: Energy-aware Hyperparameter and Architecture Search Benchmark},
author={Dou, Shuguang and JIANG, XINYANG and Zhao, Cai Rong and Li, Dongsheng},
booktitle={International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=n-bvaLSCC78},
note={ICLR 2023 notable top 25%}
}
Code
Code is available online in ths github repository: https://github.com/microsoft/EA-HAS-Bench.