Human Co-Parsing Guided Alignment for Occluded Person Re-identification
Shuguang Dou
Cairong Zhao*
Xinyang Jiang
Shanshan Zhang, Memeber, IEEE
Wei-Shi Zheng
Wangmeng Zuo, Senior Member, IEEE
Abstract
Occluded person re-identification (ReID) is a challenging task due to more background noises and incomplete foreground information. Although existing human parsing-based ReID methods can tackle this problem with semantic alignment at the finest pixel level, their performance is heavily affected by the human parsing model. Most supervised methods propose to train an extra human parsing model aside from the ReID model with cross-domain human parts annotation, suffering from expensive annotation cost and domain gap; Unsupervised methods integrate a feature clustering-based human parsing process into the ReID model, but lacking supervision signals brings less satisfactory segmentation results. In this paper, we argue that the pre-existing information in the ReID training dataset can be directly used as supervision signals to train the human parsing model without any extra annotation. By integrating a weakly supervised human co-parsing network into the ReID network, we propose a novel framework that exploits shared information across different images of the same pedestrian, called the Human Co-parsing Guided Alignment (HCGA) framework. Specifically, the human co-parsing network is weakly supervised by three consistency criteria, namely global semantics, local space, and background. By feeding the semantic information and deep features from the person ReID network into the guided alignment module, features of the foreground and human parts can then be obtained for effective occluded person ReID. Experiment results on two occluded and two holistic datasets demonstrate the superiority of our method. Especially on Occluded-DukeMTMC, it achieves 70.2% Rank-1 accuracy and 57.5% mAP.
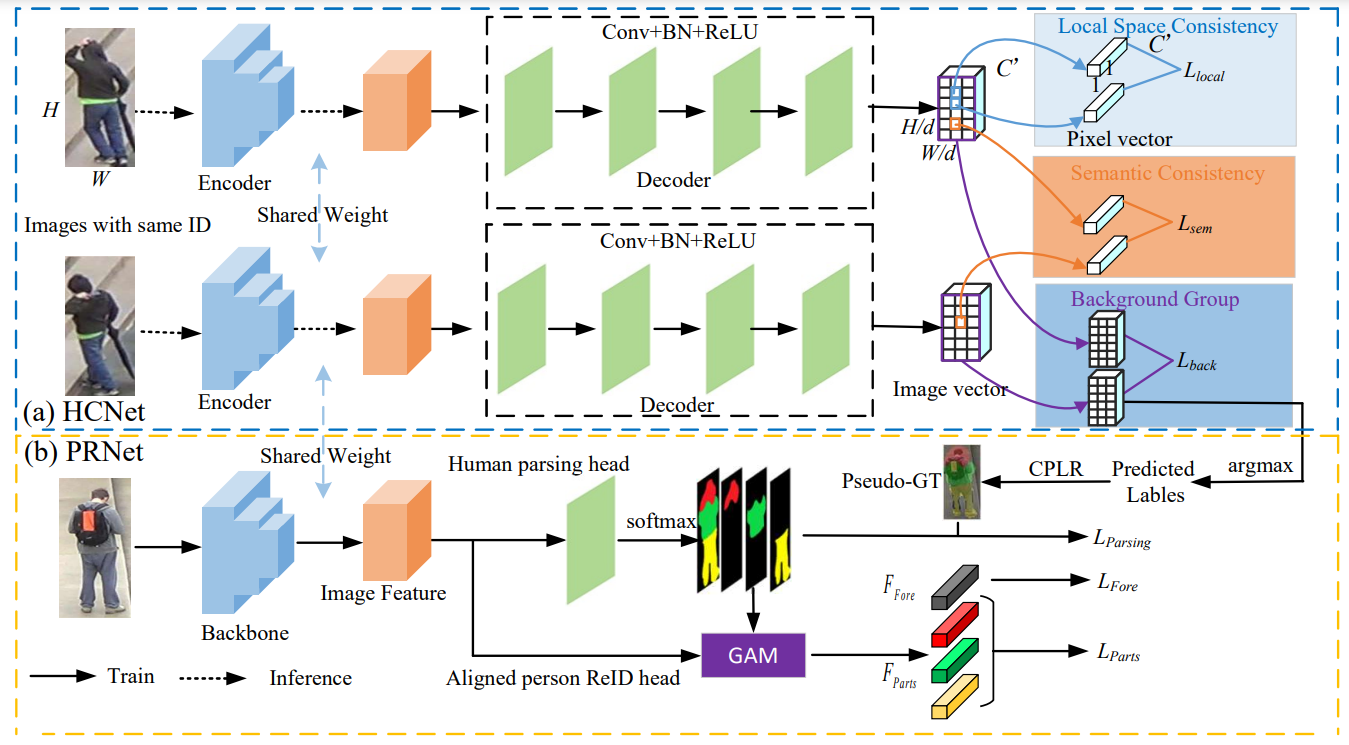
Figure 1.The flowchart of the proposed HCGA framework. (a) Human Co-parsing network (HCNet). (b) Person ReID network (PRNet). The proposed HCGA consists of HCNet and PRNet. The two sub-networks share the backbone and are trained alternately until optimized to the best. Specifically, PRNet refines the parameters to make the difference between features with different semantics greater. HCNet yields better segmentation results based on the refined features to guide PRNet alignment at the pixel level.
To illustrate our approach and verify the generality of HCNet, we apply HCNet directly on the RGB image rather than on the feature map extracted by the encoder. The RGB pixel values of a set of images with the same ID are normalized and then fed into the decoder. As shown in the following Figure, the predicted labels are haphazard at epoch 1. The background and foreground are gradually separated with the network convergence. The best results of segmentation are achieved at epoch 20 when the unique predicted labels converge to a certain number. If the network continues to converge, the objective function is close to 0 and all pixels of images are assigned to one label. This is the reason that we set the minimum number of unique predicted labels in Algorithm 1. Due to the direct use of pixel values as input, the segmentation network may fail when the color and texture of the background and foreground are similar. Therefore, we use the deep network with an encoder-decoder structure. Besides, the proposed method can segment the blue bag in the hand of the pedestrian from the background compared with Human parsing
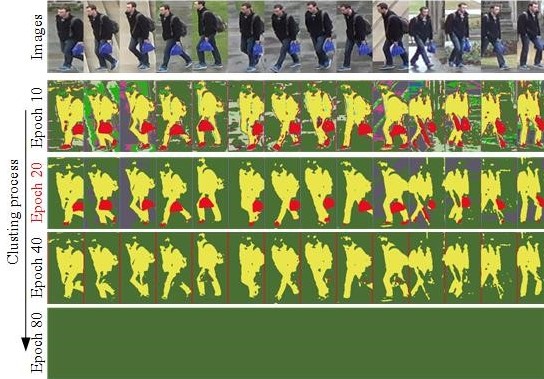
Figure 2. Visualization of the clustering process of HCNet trained directly on RGB images with the same ID. Different colors indicate different clustering categories, where green and gray are background categories and yellow and red are foreground categories. The training process is represented from top to bottom and is best viewed in color.
In this work, we propose a Human Co-parsing Guided Alignment (HCGA) framework for the task of person ReID. We design local spatial consistency, semantic consistency, and background group losses to weakly supervise the human co-parsing network. The parsing result generated by HCNet guides PRNet to be aligned at the pixel level. PRNet uses a guided alignment module to reduce the uncertainty of segmentation prediction. During inference, only PRNet is used to obtain foreground features and human parts features for matching. Experimental results show that the proposed framework is effective for both holistic and occlusion person ReID problems. Moreover, the visualization results demonstrate that weakly supervised human co-parsing has great potential for occluded person ReID.
Paper
- Paper: PDF
Please consider citing if this work and/or the corresponding code are useful for you:
@article{hcga22tip,
author={Dou, Shuguang and Zhao, Cairong and Jiang, Xinyang and Zhang, Shanshan and Zheng, Wei-Shi and Zuo, Wangmeng},
journal={IEEE Transactions on Image Processing},
title={Human Co-Parsing Guided Alignment for Occluded Person Re-Identification},
year={2023},
volume={32},
pages={458-470},
doi={10.1109/TIP.2022.3229639}}
}
Code
Code is available online in ths github repository: https://github.com/Vill-Lab/2022-TIP-HCGA.