EA-HAS-Bench: Energy-Aware Hyperparameter and Architecture Search Benchmark
Shuguang Dou
Xinyang Jiang*
Cairong Zhao*
Dongsheng Li
Abstract
The energy consumption for training deep learning models is increasing at an alarming rate due to the growth of training data and model scale, resulting in a negative impact on carbon neutrality. Energy consumption is an especially pressing issue for AutoML algorithms because it usually requires repeatedly training large numbers of computationally intensive deep models to search for optimal configurations. This paper takes one of the most essential steps in developing energy-aware (EA) NAS methods, by providing a benchmark that makes EANAS research more reproducible and accessible. Specifically, we present the first large-scale energy-aware benchmark that allows studying AutoML methods to achieve better trade-offs between performance and search energy consumption, named EA-HAS-Bench. EA-HAS-Bench provides a large-scale architecture/hyperparameter joint search space, covering diversified configurations related to energy consumption. Furthermore, we propose a novel surrogate model specially designed for large joint search space, which proposes a Bezier curve-based model to predict learning curves with unlimited shape and length. Based on the proposed dataset, we modify existing AutoML algorithms to consider the search energy consumption, and our experiments show that the modified energy-aware AutoML methods achieve a better trade-off between energy consumption and model performance.
We present the first large-scale energy-aware benchmark that allows studying AutoML methods to achieve better trade-offs between performance and search energy consumption, named EA-HAS-Bench. EA-HAS-Bench provides a large-scale architecture/hyperparameter joint search space, covering diversified configurations related to energy consumption. Furthermore, we propose a novel surrogate model specially designed for large joint search space, which proposes a Bezier curve-based model to predict learning curves with unlimited shape and length.
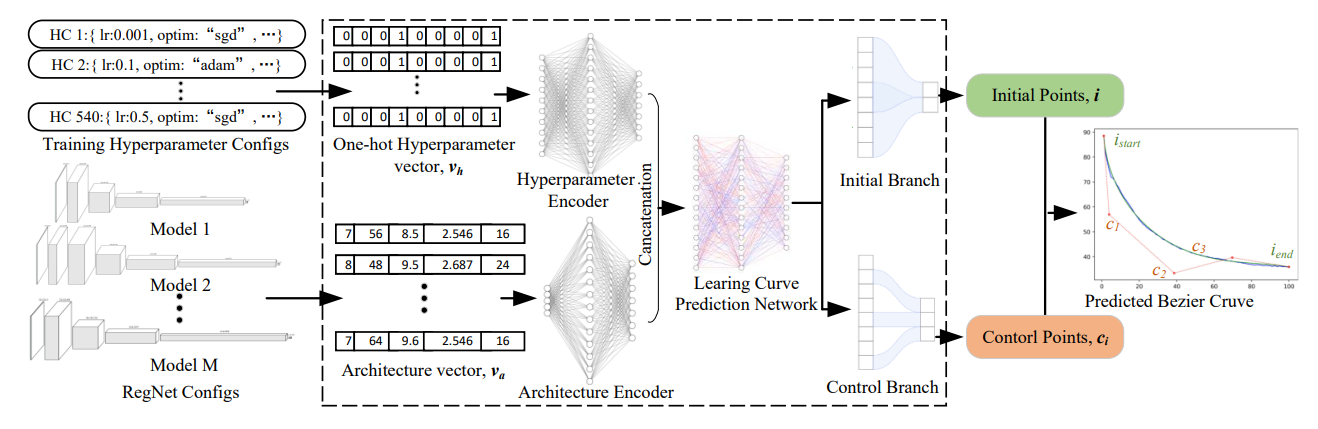
Figure 1.Overview of Bezier Curve-based Surrogate Model. HC denotes Hyperparameter configuration.
Most of the existing conventional benchmarks like NAS-Bench-101 do not directly provide training energy cost but use model training time as the training resource budget, which as verified by our experiments, is an inaccurate estimation of energy cost. HW-NAS-bench provides the inference latency and inference energy consumption of different model architectures but also does not provide the search energy cost.
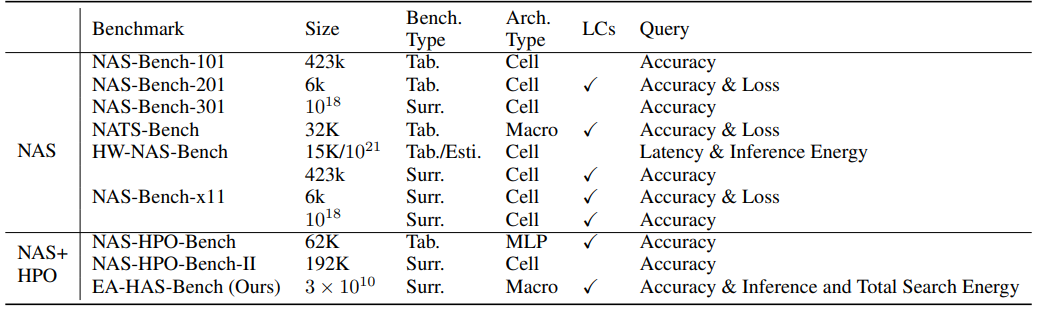
Dataset Overview
EA-HAS-Bench’s Search Space
Unlike the search space of existing mainstream NAS-Bench that focuses only on network architectures, our EA-HAS-Bench consists of a combination of two parts: the network architecture space- RegNet and the hyperparameter space for optimization and training, in order to cover diversified configurations that affect both performance and energy consumption. The details of the search space are shown in Table.
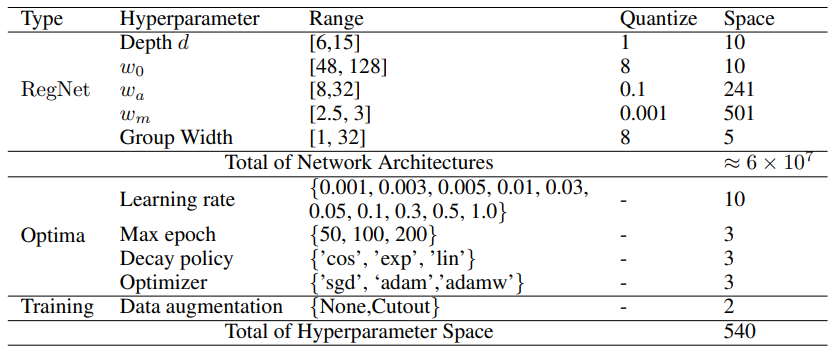
Evaluation Metrics
The EA-HAS-Bench dataset provides the following three types of metrics to evaluate different configurations:
- Model Complexity: parameter size, FLOPs, number of network activations (the size of the output tensors of each convolutional layer), as well as the inference energy cost of the trained model.
- Model Performance: full training information including training, validation, and test accuracy learning curves.
- Search Cost: energy cost (in kWh) and time (in seconds).
Dataset Statistics
The left plot shows the validation accuracy box plots for each NAS benchmark in CIFAR-10. The right plot shows a comparison of training time, training energy consumption (TEC), and test accuracy in the dataset.
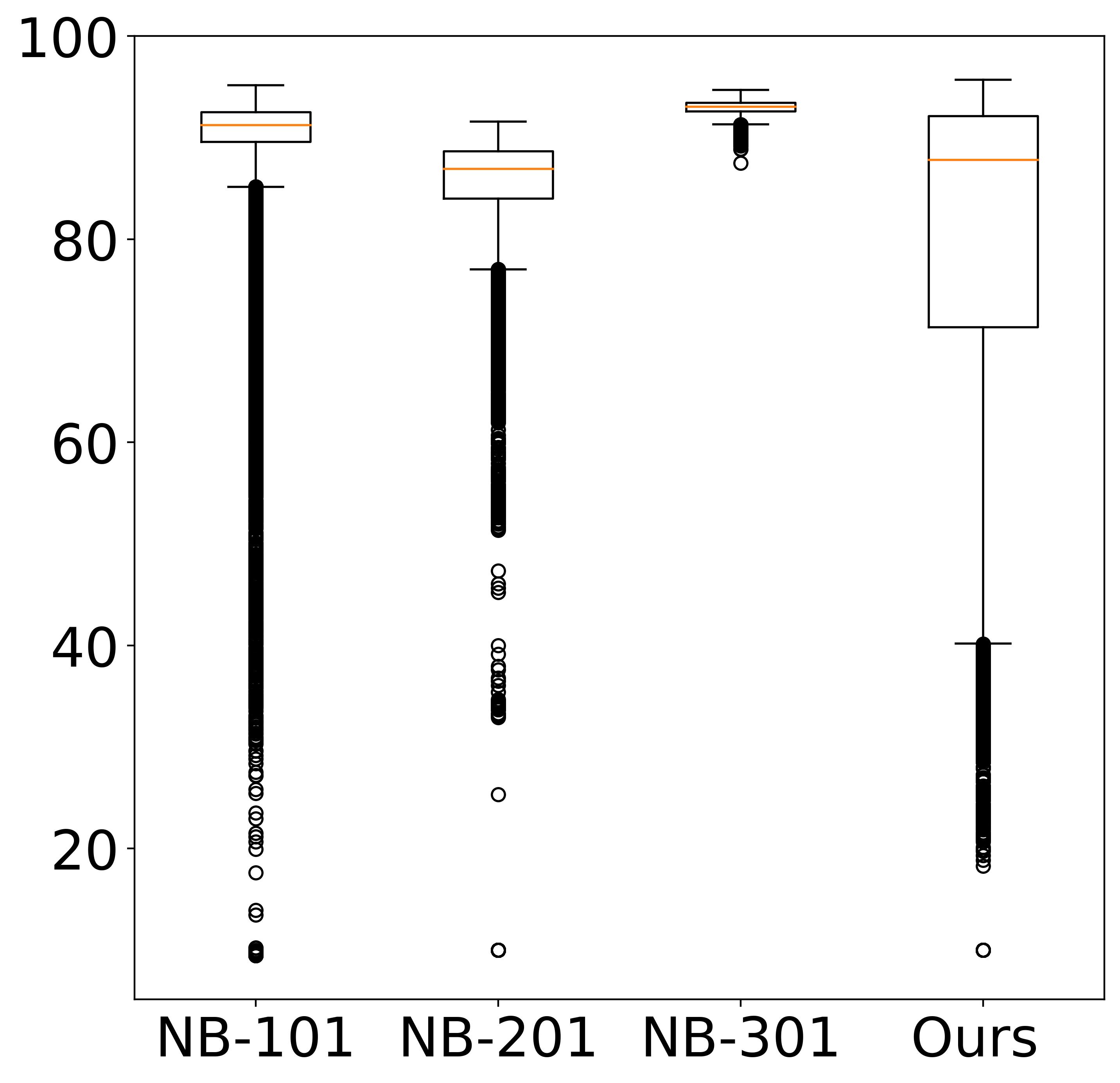
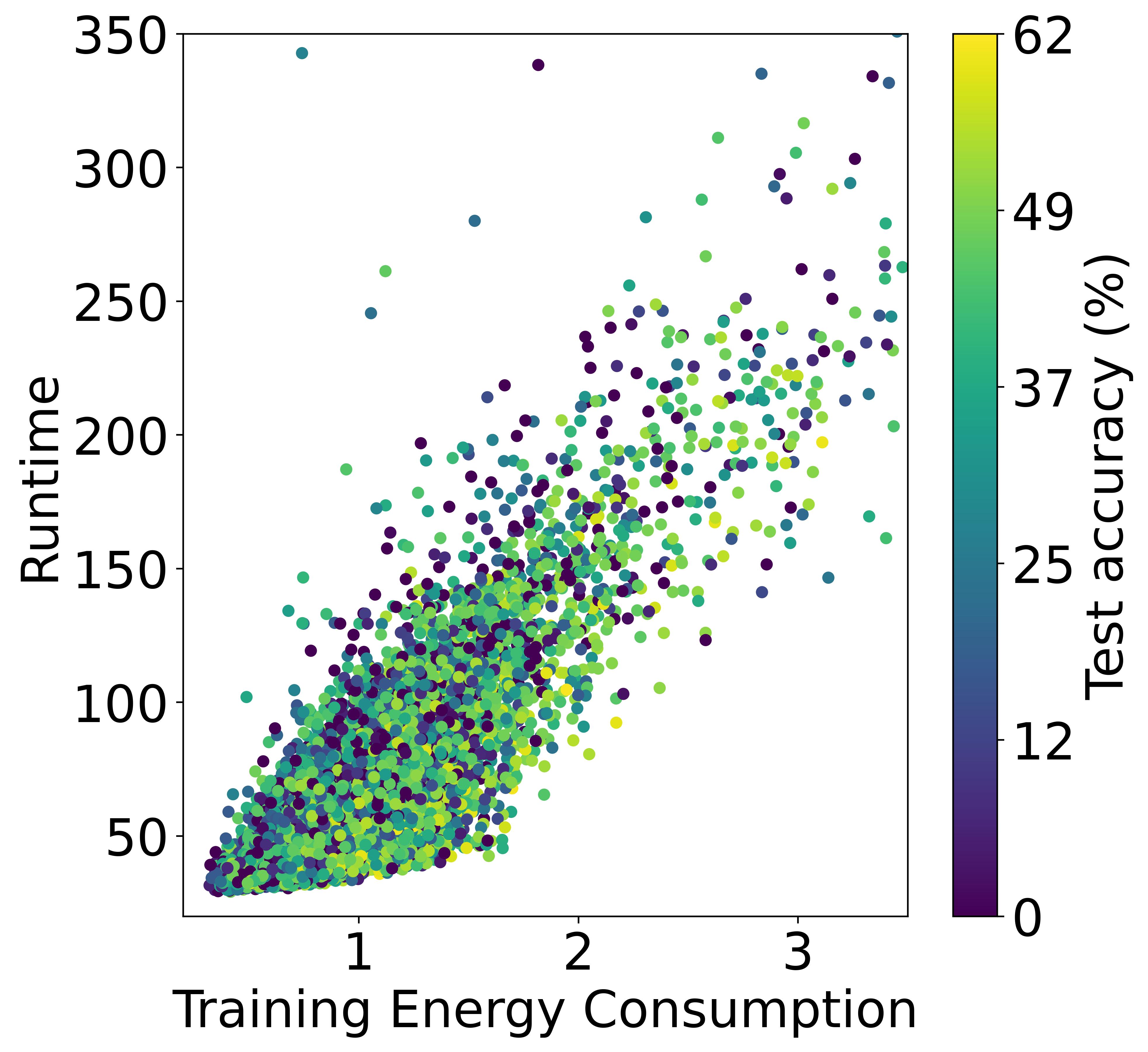
Although training the model for a longer period is likely to yield a higher energy cost, the final cost still depends on many other factors including power (i.e., consumed energy per hour). The left and right plots of Figure also verifies the conclusion, where the models in the Pareto Frontier on the accuracy-runtime coordinate (right figure) are not always in the Pareto Frontier on the accuracy-TEC coordinate (left figure), showing that training time and energy cost are not equivalent.
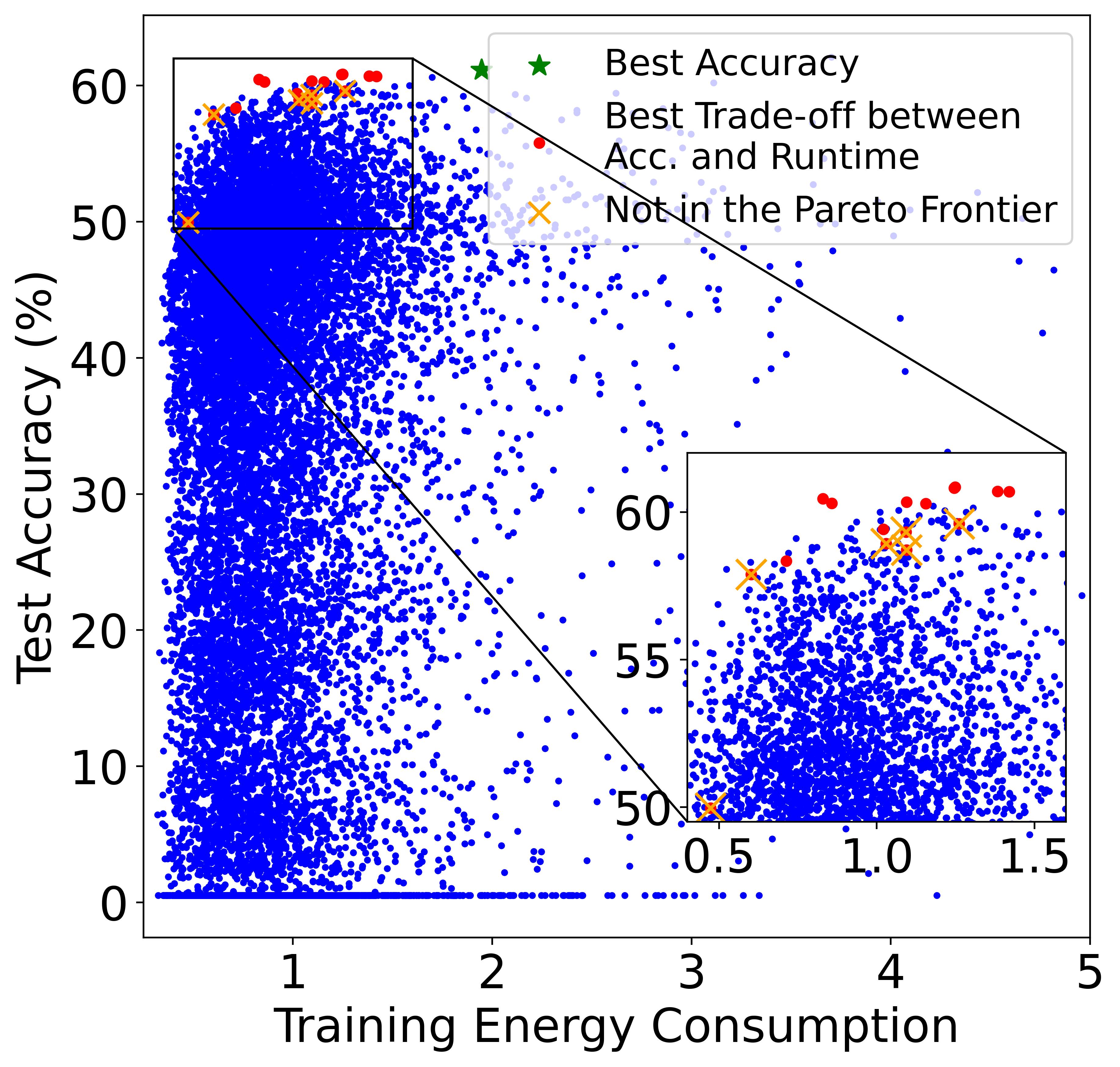
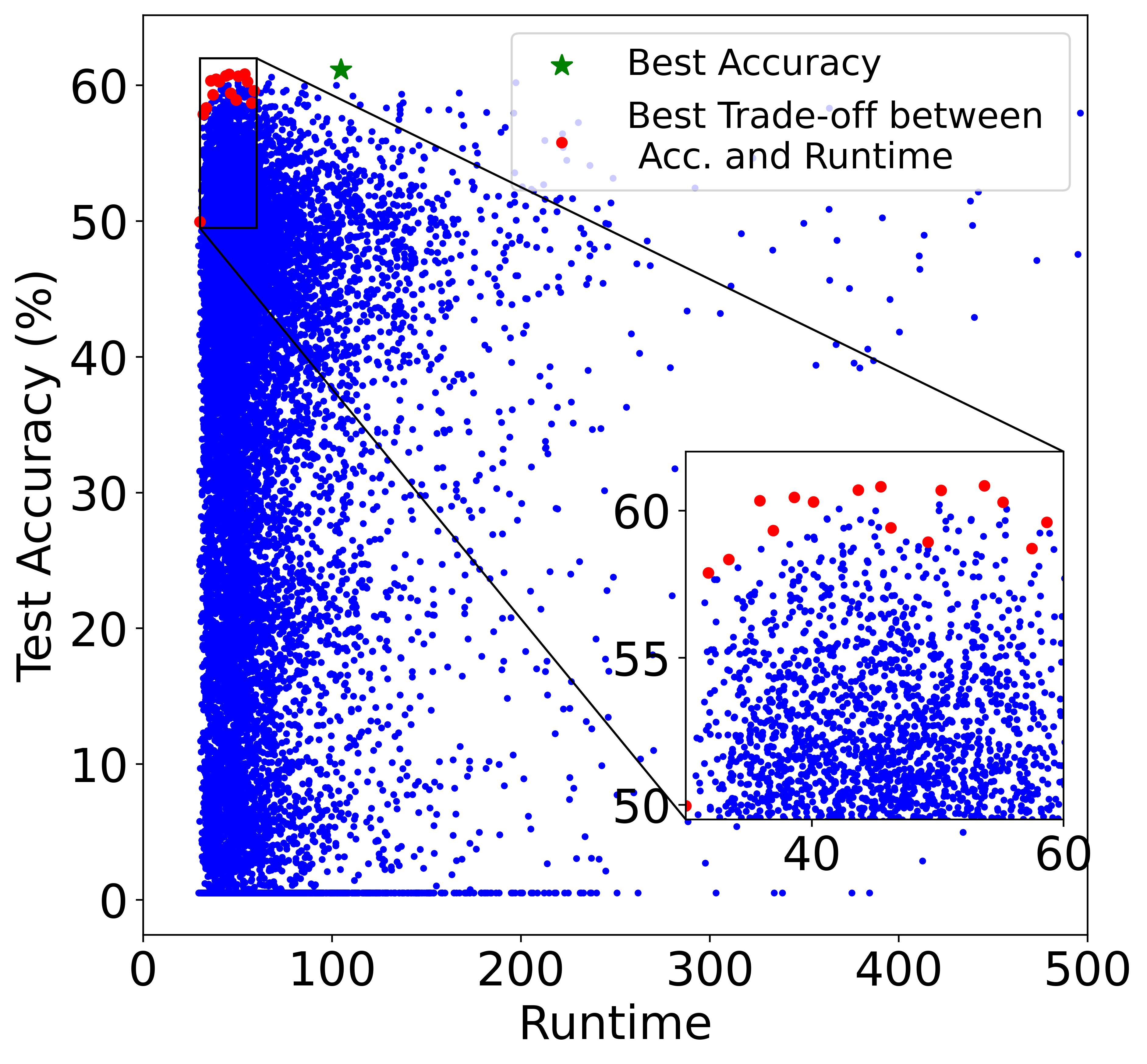
Paper
- Paper: PDF
Please consider citing if this work and/or the corresponding code and dataset are useful for you:
@inproceedings{ea23iclr,
title={EA-HAS-Bench: Energy-aware Hyperparameter and Architecture Search Benchmark},
author={Dou, Shuguang and JIANG, XINYANG and Zhao, Cai Rong and Li, Dongsheng},
booktitle={International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=n-bvaLSCC78},
note={ICLR 2023 notable top 25%}
}
Code
Code is available online in ths github repository: https://github.com/microsoft/EA-HAS-Bench.